Blog Build Crashes Due to Memory Shortage - 70% Bundle Size Reduction Strategy
Introduction
I started working to reduce the blog's bundle size in January and am only now documenting the process.
This blog is hosted on Vercel. However, since one day in January, the blog deployments have been failing continuously.
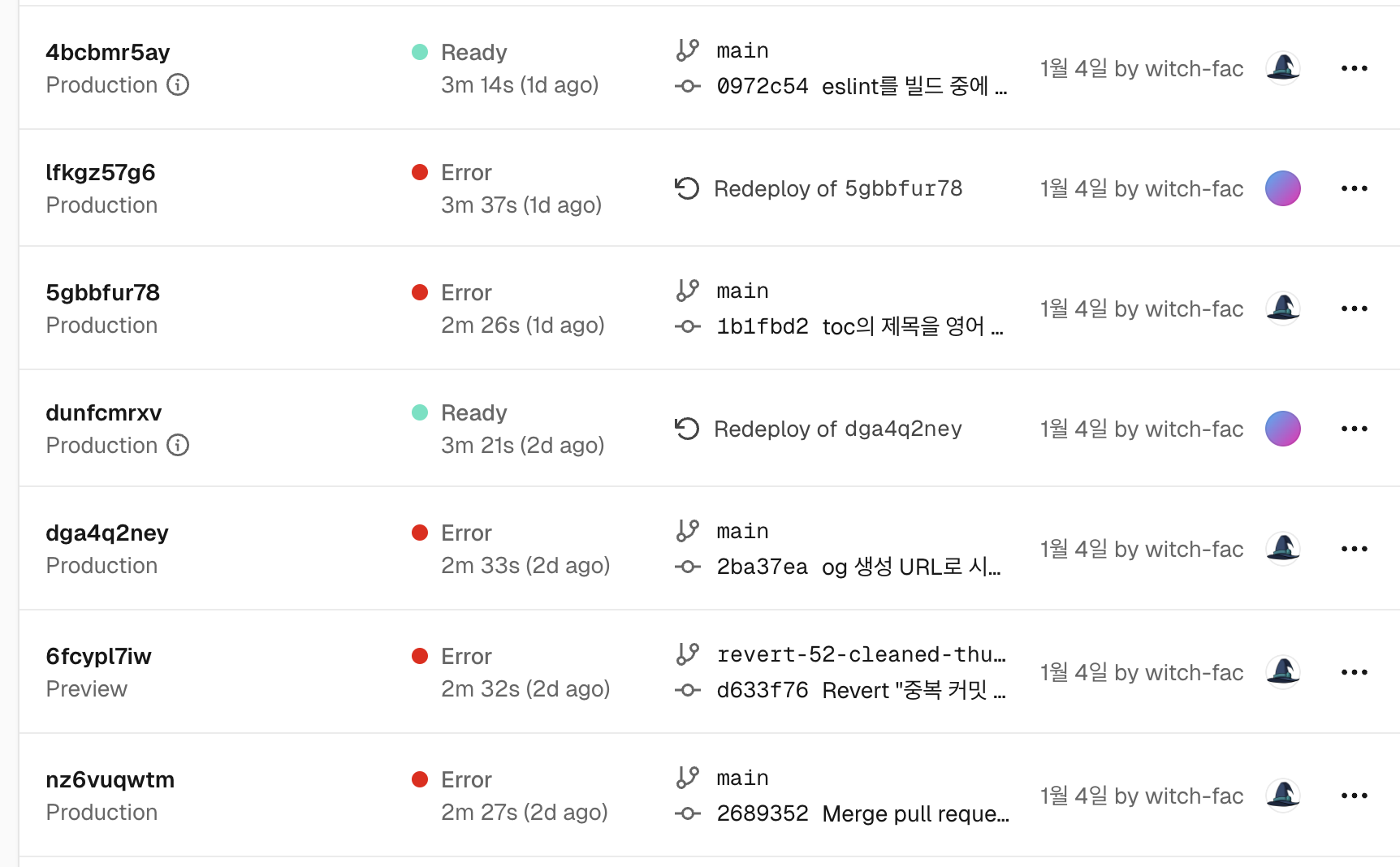
Looking into the deployment logs, the build fails with a SIGKILL error. It seems there is an issue.
Error: Command "pnpm run build" exited with SIGKILL
Vercel had posted an article about this. It states that Vercel's build container allocates 8GB of memory, and if the project exceeds this memory, the build fails with a SIGKILL error.
Checking the Build Diagnostics in Vercel Observability, I confirmed that memory usage during builds was spiking to 80-90% (even when builds succeed).
When I started supporting the English version of the blog, the number of pages increased to about 650, which seems to be the cause. If the blog grows further, building will become even harder. So, I decided to address this issue.
The article from Vercel outlines several potential causes, but most stem from handling excessively large data. Thus, I aimed to reduce the bundle size and concluded that code highlighting and the search page were the key culprits contributing to the increased bundle size.
Here, I will write about the process leading to the identification of these issues and their solutions.
Previous Attempts
Bundle Analysis Tool
Next.js provides a tool to analyze the bundle size. Let's try it according to the official documentation.
First, install the next-bundle-analyzer.
pnpm add @next/bundle-analyzer
Then, add the following configuration to next.config.js.
const withBundleAnalyzer = require('@next/bundle-analyzer')({
enabled: process.env.ANALYZE === 'true',
});
module.exports = withBundleAnalyzer(nextConfig)
Now, run the build command, and you will be able to see the bundle analysis results. Once the build is complete, three browser tabs will open showing the bundle analysis results.
ANALYZE=true pnpm run build # Build with analysis
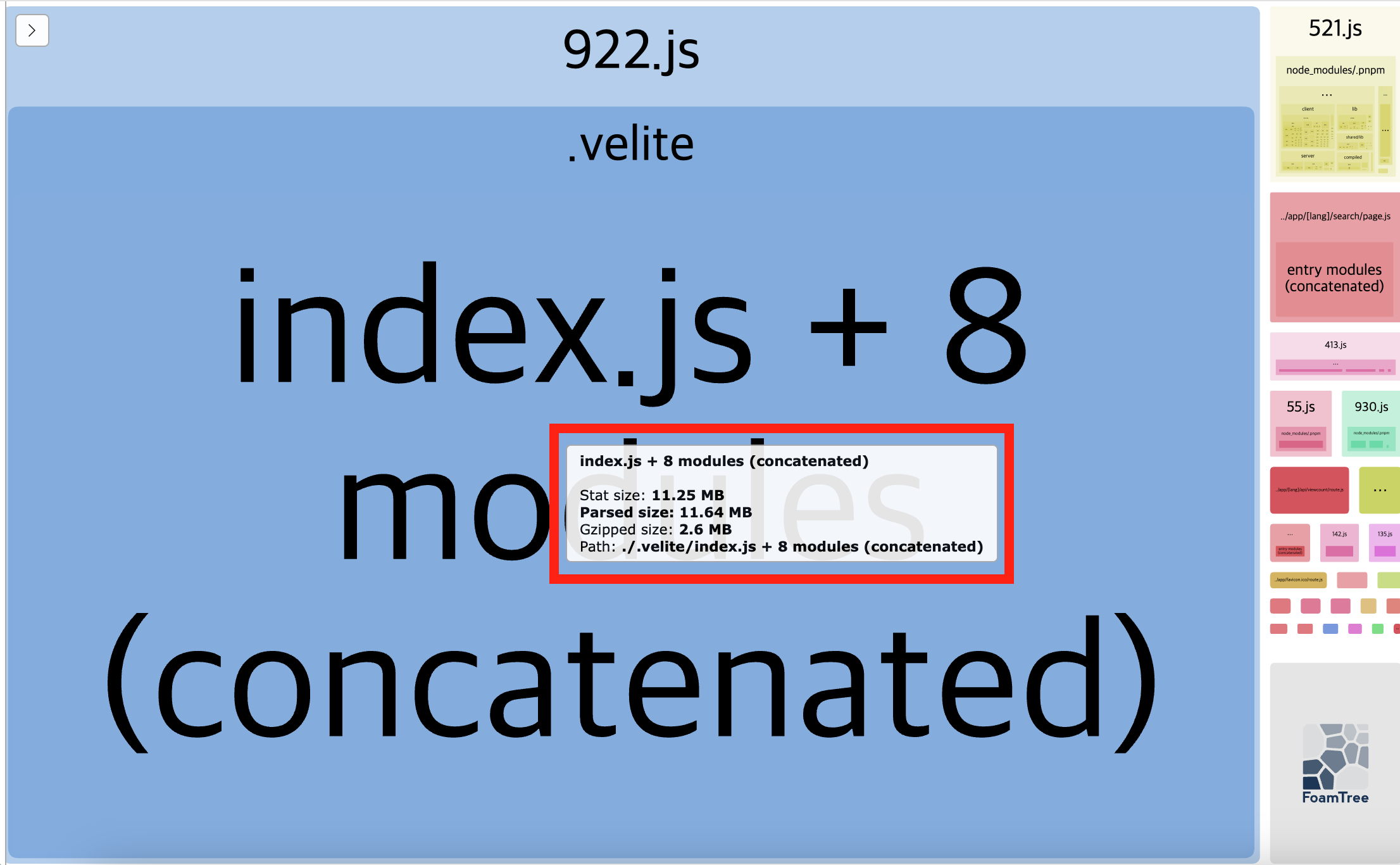
The output result is roughly as follows.

Currently, the items occupying a significant portion are:
app/[lang]/posts/page.js(Search Page)- Parsed size: 39.2MB
- Gzipped size: 3.16MB
- Items generated by velite (blog content management system)
- Parsed size: 38.7MB
- Gzipped size: 3.15MB
I needed to find a way to reduce these.
Disabling Static Checks During Build
Next.js runs eslint and TypeScript checks during the build and halts if there are related errors. However, these static checks can consume a lot of memory. My blog's code size isn't particularly large, so I didn't suspect this initially, but I decided to disable them.
I added the following settings in next.config.js to turn off eslint and TypeScript checks during the build.
const nextConfig = {
// ...
eslint: {
ignoreDuringBuilds: true,
},
typescript: {
ignoreBuildErrors: true,
},
};
The build time improved slightly, but there was no significant change in bundle size or memory usage during the build as seen in Vercel Observability.
Package Optimization Options
I thought there might be an issue with how modules were imported, so I set up a configuration to only import modules that are actually used. I configured next.config.js with experimental.optimizePackageImports.
const nextConfig = {
// ...
experimental: {
optimizePackageImports: ['react', 'react-dom'],
}
};
However, there were no significant changes even after trying other dependency libraries.
Issue Analysis
It seemed a more fundamental solution was needed, so I reconsidered. What currently takes up the most space in the bundle size? It's the transformed data of blog posts. The data in .velite and the data loaded from the search page fundamentally come from the blog post data.
So, what is the original size of the blog posts? Realistically, it would be difficult to reduce this below the original size stored in markdown, so if I knew the size of the original markdown files, I could estimate a target size.
Since all blog posts are in .md files, I can run the following command in the content folder to add up the sizes of all markdown files in KB.
$ find . -name "*.md" -exec du -k {} + | awk '{total+=$1} END {print total " KB"}'
7256 KB
That's about 7.09MB. Thus, my practical goal for reducing the transformed result would likely be to get below 7MB (though it could theoretically go lower with encoding, I don't see the need for that). Currently at 40MB, I believe reducing it is achievable.
The main goal isn't to turn off eslint but to discover why this 7MB size ballooned to 40MB and to resolve that issue. The size of dependency libraries pales in comparison.
Reducing Search Page Bundle Size
Consideration
Thinking about the logic of the search page, it currently fetches all existing post data and displays all posts containing the search term. Thus, the bundle size of the search page naturally follows the size of post data.
There are two options to consider.
First, one option is to move the search logic to the server. By implementing debouncing, I could send the appropriate search query to the server upon changes to the search term, and the route handler would process this and send a response. If I made the search a form submission that required clicking a "Search" button rather than responding in real-time, it might even be possible to create the search page as a server component.
However, that attempt failed. I initially tried to execute the search on the server using libraries like flexsearch. This worked to create the search page as a server component, but it was too slow. The route handler provided by Vercel seemed too weak to handle this kind of search. While tools like Algolia could handle it, they come with costs.
The second option is to reduce the data being searched. The blog posts exceed 7MB in text size. Could I optimize this search as a frontend developer? It would be challenging with my existing knowledge. Therefore, I decided to only include titles and summaries of the posts for searching, drastically reducing the data to be handled on the search page. Thus, the data needed for the search page would only be a few thousand characters.
Creating New Data
Let's create a new data schema in the velite library that manages blog content. It's important to note that how velite operates here isn't crucial, so you can simply understand it as creating a simple data object that includes only the title and summary of the blog posts, excluding the content.
export const metadataObject = s.object({
slug: postSlug(),
title: s.string().max(99),
date: s.string().datetime(),
description: s.string().max(200),
thumbnail: s.object({
local: s.string(),
cloud: s.string().optional(),
blurURL: s.string().optional(),
}).optional(),
});
export const articleMetadataObject = metadataObject.extend({
tags: s.array(s.string()),
});
export const articleMetadataSchema = defineSchema(() =>
articleMetadataObject.transform((data) => ({ ...data, url: `/posts/${data.slug}` })),
);
Then, use this schema in the velite configuration file to generate data from the .md files.
const postMetadata = defineCollection({
name: 'PostMetadata', // Collection type name
pattern: 'posts/**/*.md', // Content files glob pattern
schema: articleMetadataSchema(),
});
// Now, we can add the postMetadata Collection to the velite configuration through defineConfig
Applying to Search Page
Next, let's use this new data in the search page. The current search data is managed by a function called getSearchPosts, which returns the data filtered by the search term. I believe this is a standard search logic, so I will skip further explanation.
Therefore, we just need to change the return data in getSearchPosts from the complete post data to the PostMetadata.
// Before change
export const getSearchPosts = (lang: Locale = 'ko') => {
const allPosts = sortByDate([...(lang === 'ko' ? posts : enPosts)]);
return allPosts.map((post) => searchProperty(post));
};
// After change
export const getSearchPosts = (lang: Locale = 'ko') => {
const allPosts = sortByDate([...(lang === 'ko' ? postMetadata : enPostMetadata)]);
return allPosts.map((post) => searchProperty(post));
};
Unfortunately, this means that searching blog content is no longer possible on the search page. Now, it can only search by title and summary. However, the bundle size? It has been reduced to under 500KB.
Code Highlighting Optimization
Now it's time to reduce the size of the transformed data of blog posts. In fact, the bundle size of the search page was merely a reflection of the size of this transformed data, making it the real issue. How can we prevent 7MB of data from becoming 40MB?
Issue Analysis
The velite library I use for blog content management converts blog post data into .json.
However, this conversion does not happen directly. Code highlighting and transformations for LaTeX syntax must occur, and it generates a table of contents. These tasks are handled by remark and rehype plugins, which transform the content into a displayable format. I strongly suspected that this process was responsible for the increase in size.
I checked each plugin in the velite settings by turning them off and building to see which plugin inflated the bundle size the most. By disabling the rehype plugin related to code highlighting, the bundle size shrank to about 7.2MB, very close to the original size.
Upon further inspection, the rehype-pretty-code plugin was the culprit. This plugin inlines all the color styles of all the themes I use on the blog. I have four themes, meaning highlighted keywords are rendered like this:
<span style="--shiki-light:#E36209;--shiki-pink:#001080;--shiki-dark:#FFAB70;--shiki-darkPink:#FFAB70">index</span>
Additionally, rehype-pretty-code includes some inefficient CSS properties. For instance, it wraps each keyword in a tag, even when they could be highlighted by a single tag.
However, I can't skip code highlighting in a tech blog. There are many code examples. Therefore, I decided to try using another rehype plugin called rehype-highlight, which supports code highlighting. After applying it, the size of the velite transformation result fell to around 11-12MB, which was a significant reduction. The build time also decreased by over 50%.
Rehype-highlight isn't without its downsides. Since highlight.js operates on a regex basis, code highlighting can occasionally be less accurate or fail to render properly.
For example, in the syntax highlighting for C language, the #include can be seen as a single keyword. However, for some reason, it gets highlighted as # and include separately. Similarly, the highlighting for the bash language fell short.
While rehype-highlight has many shortcomings compared to rehype-pretty-code regarding highlighting quality, the urgency of addressing the excessive bundle size takes precedence. As a tech blog, the content is more important than having flawless code highlighting. Thus, I decided to implement this change.
Applying rehype-highlight
First, in the velite configuration file, I replaced rehype-pretty-code with rehype-highlight.
export default defineConfig({
// ...
// Area to apply plugins for markdown conversion
markdown: {
remarkPlugins: [remarkMath, remarkHeadingTree],
rehypePlugins: [
// [rehypePrettyCode, rehypePrettyCodeOptions],
rehypeKatex,
[rehypeHighlight],
],
},
// ...
});
Rehype-highlight wraps found keywords with appropriate classes in <span>, like this when dealing with strings in a code block:
<span class="hljs-string">'use client'</span>
However, the highlighting won't work right away because the colors for those classes haven't been defined yet. This can be resolved by importing CSS files from the styles folder of highlight.js, which contain defined color styles for each class.
Since my blog uses different themes, I made adjustments to ensure appropriate highlighting themes are applied based on the blog theme. For instance, the CSS file used for the light theme works only under the lightTheme class, and these files are stored in the src/styles/syntax folder.
// src/styles/syntax/github-light.css.ts
globalStyle(`
${lightTheme} .hljs`,
{
color: '#24292e',
});
globalStyle(`
${lightTheme} .hljs-doctag,
${lightTheme} .hljs-keyword,
${lightTheme} .hljs-meta .hljs-keyword,
${lightTheme} .hljs-template-tag,
${lightTheme} .hljs-template-variable,
${lightTheme} .hljs-type,
${lightTheme} .hljs-variable.language_`,
{
color: '#d73a49',
});
// ...
For the light theme, I used github-light, for dark theme I used github-dark, for pink theme I implemented panda-syntax-light, and for dark pink theme I used panda-syntax-dark.
Yet, there's still a problem. While languages like JavaScript highlight well, several other languages do not highlight correctly.
It turns out rehype-highlight supports 37 default languages, and it needs the functionality from lowlight to highlight other languages. The list of languages supported by lowlight can be found here.
I examined each programming language used in my blog posts to determine which ones were not highlighted. Among the programming languages used in my blog examples, those that were not supported by rehype-highlight included lisp, nginx, dockerfile, and prisma (though the classification of nginx as a language could be debated, its structured syntax can benefit from highlighting).
Fortunately, lowlight supports lisp, nginx, and dockerfile. Therefore, I need to register their syntax packages with rehype-highlight by referring to the registration section of rehype-highlight.
To apply the necessary files from lowlight and highlight.js, I first installed both libraries.
pnpm add -D lowlight highlight.js
Then, I registered the languages in the rehype-highlight options.
// velite.config.ts
import { common } from 'lowlight';
import lisp from 'highlight.js/lib/languages/lisp';
import nginx from 'highlight.js/lib/languages/nginx';
import dockerfile from 'highlight.js/lib/languages/dockerfile';
const rehypeHighlightOptions = {
languages: {
...common,
lisp,
nginx,
dockerfile,
}
}
export default defineConfig({
// ...
// Add rehype-highlight options to markdown options
markdown: {
remarkPlugins: [/* remark plugins */],
rehypePlugins: [
// ...
[rehypeHighlight, rehypeHighlightOptions],
],
},
});
Adding Prisma Highlighting
However, prisma syntax highlighting is not supported by lowlight. I found an issue on GitHub requesting this feature for highlight.js.
Unfortunately, highlight.js is no longer accepting requests for new languages. If it's needed, I have to implement a custom solution for syntax highlighting and create a third-party plugin. It seems no significant progress has been made on the prisma highlighting issue, so I will likely have to create my plugin using rehype-highlight for prisma.
This task doesn’t seem easy. However, since it could reduce the bundle size significantly from 40MB to 12MB, it's worth pursuing. I believe it's essential to see things through. I discussed this mindset a bit in my blog post about the art of exploration - contributing a sentence to MDN and reading papers.
Fortunately, I found some resources that could assist with my work in the prisma issue, such as the syntax file used in the Prisma vscode extension.
Also, I could refer to the following resources for highlight.js:
- Language definition guide
- Language contributor checklist
- Third-party contribution guide
- Other language definitions in the
src/languagefolder
I am not an expert in highlight.js utilities and do not primarily use prisma, which made the process quite difficult. However, let’s move on since this isn’t the focus of this article. I wrote functions that match keywords with regex and placed them in src/bin/prisma-highlight.js.
// src/bin/prisma-highlight.js
/** @type LanguageFn */
export default function highlight(hljs) {
// ... omitted code ...
const NUMBER = {
scope: 'number',
match:
/((0(x|X)[0-9a-fA-F]*)|(\+|-)?\b(([0-9]+(?:\.[0-9]*)?)|(\.[0-9]+))((e|E)(\+|-)?[0-9]+)?)(?:[LlFfUuDdg]|UL|ul)?\b/,
};
// ... omitted code ...
const MODEL_BLOCK_DEFINITION = {
begin: [/(model|type|view)/, /\s+/, /([A-Za-z][\w]*)/, /\s*/, /({)/],
beginScope: {
1: 'keyword',
3: 'title.class',
5: 'punctuation',
},
end: /\s*}/,
endScope: 'punctuation',
contains: [COMMENTS, FIELD_DEFINITION, ATTRIBUTE_WITH_ARGUMENT, ATTRIBUTE],
};
return {
name: 'Prisma schema language',
case_insensitive: true,
keywords: {
keyword: KEYWORDS,
type: TYPES,
literal: ['true', 'false', 'null'],
},
contains: [
COMMENTS,
MODEL_BLOCK_DEFINITION,
CONFIG_BLOCK_DEFINITION,
ENUM_BLOCK_DEFINITION,
TYPE_DEFINITION,
],
};
}
If this plugin is truly necessary, you can use the guides above and my blog's src/bin/prisma-highlight.js as reference.
Then, just register it in the rehype-highlight options used in velite.
import prisma from '@/bin/prisma-highlight';
const rehypeHighlightOptions = {
languages: {
...common,
lisp,
nginx,
dockerfile,
// My custom prisma added here
prisma,
}
}
// The rest remains the same
What will the outcome be? Will Prisma's syntax highlighting work well? There might be some issues such as with enum, but simple Prisma schema definitions like the one below are highlighted correctly.
// Prisma schema definition
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
profile Profile?
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
}
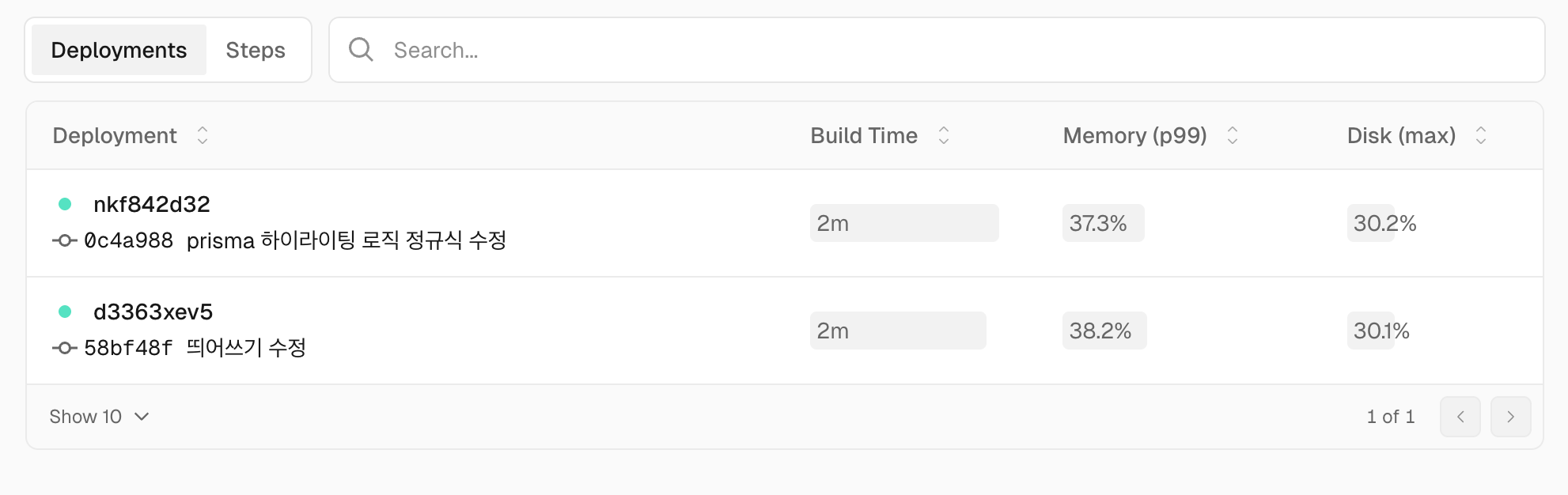
What about the bundle size? Let's run pnpm analyze again. The bundle size for the search page is now under 500KB, and the transformed data size for blog posts is around 11.64MB. I am satisfied with these results.
Now the build completes comfortably, with memory usage dropping below 40%.
Since I went through the effort of creating a third-party solution, I also separated and published the highlighting repository as highlightjs-prisma. You can find it here, set up for others to use.
I hope this can be helpful for anyone who faces similar issues or needs to highlight Prisma with highlight.js.
Conclusion
To resolve the issue of builds terminating due to excessive memory usage resulting in SIGKILL, I undertook efforts to reduce the bundle size.
Through improving the search page structure, changing code highlighting plugins, and removing unnecessary data, I managed to reduce the bundle size from about 40MB (considering the search page, even double that) to a total of approximately 12MB.
It was challenging. I had to create a new data object, learn how to utilize highlight.js, and even develop a third-party plugin. However, the blog builds now complete smoothly and run much faster than before.
The features I lost are negligible. Even though rehype-pretty-code offered many more features, I wasn't using those on my blog, so it doesn’t matter. I hope my efforts provide some assistance to someone out there.
References
Troubleshooting Builds Failing with SIGKILL or Out of Memory Errors
https://vercel.com/guides/troubleshooting-sigkill-out-of-memory-errors
Next.js docs, Optimizing Package Bundling
https://nextjs.org/docs/app/building-your-application/optimizing/package-bundling
Next.js docs, optimizePackageImports
https://nextjs.org/docs/app/api-reference/config/next-config-js/optimizePackageImports
How we optimized package imports in Next.js
https://vercel.com/blog/how-we-optimized-package-imports-in-next-js
Lowlight README CSS section
https://github.com/wooorm/lowlight?tab=readme-ov-file#css
rehype-highlight README
https://github.com/rehypejs/rehype-highlight?tab=readme-ov-file
Prisma issue #2337, Add Prisma syntax to highlight.js