Using Prisma Markdown to Generate Documentation from Prisma Schema
This document explains the background of adopting prisma-markdown in the project and briefly summarizes its usage.
1. Introduction to prisma-markdown
1.1. Background of Adoption
I am creating an attendance management system for an algorithm camp run by ICPC Sinchon. The backend is built using Prisma ORM, NodeJS, and express. The database structure was first designed using ERDCloud and then implemented in Prisma Schema. Since I was handling many parts alone, minor synchronization issues did not pose significant problems as I was aware of almost all contexts.
However, as the database design changed significantly and team members started to interact with the code that was not completely isolated from my work, issues began to arise gradually. Changes made in ERDCloud often remained unreflected in the Prisma Schema, and instances occurred where I hurriedly modified the Prisma Schema but forgot to update ERDCloud.
Additionally, even if the design was changed, it became challenging to communicate these intentions or modifications to everyone. While creating documents was an option, the information was already divided between Prisma Schema and ERDCloud, and adding another document seemed unlikely to improve the situation.
I discovered the automatic markdown documentation generator prisma-markdown created by samchon while overhearing conversations in an open chat room. Judging by the number of GitHub stars, it appeared to be a not very well-known library. However, given the creator's prominence and the nature of the current project, which would not be severely affected by minor document inaccuracies, I decided to give it a try.
1.2. User Experience
The subsequent sections of the document detail usage extensively. However, it took much longer to write this introduction than to learn and apply prisma-markdown, indicating how easy it is to adopt.
Of course, like any library, understanding its features thoroughly and documenting requires reviewing examples and investing some time. However, in scenarios where only simple visualization is needed and the model is not too large, installation and application can be completed in just one minute. All that is needed is to install the library via npm, copy the generator into the schema file, and run the command npx prisma generate. While it is not highly user-customizable, even if minimal customization such as sectioning is needed, it can be easily accomplished by consulting the official documentation.
The advantages, in comparison, are significant. If there are specific document format requirements, a need for detailed explanations regarding the domain, or a large model for a product launch, it might be worth exploring other libraries since customization options may be relatively limited and document formats predefined. However, for many projects where the database size is not extensive, prisma-markdown is incredibly useful.
First, there is no need to create separate document formats; simply starting comments with /// appropriately suffices. Further, when modifying the Prisma schema file, you no longer need to open a separate document for edits. After amending the comments, running the npx prisma generate command, which is required to reflect schema changes, automatically updates the documentation. Since it is included as a devDependency, it does not increase the bundle size, and execution speeds are very fast.
Although I am primarily a frontend developer, I often glance at backend or database table structures while working on small projects. However, synchronizing the documentation with the actual table structure can be more challenging than expected. Therefore, if you are using Prisma in a project, I recommend using prisma-markdown.
2. Installation and Setup
This document assumes that Prisma, prisma/client, and the schema are already set up. In a previous article, I installed Prisma and created the schema while configuring the server. The previous article featured a simple student schema, but the actual schema was much more complex. The following sections will utilize the actual schema. Since prisma-markdown is the focus, I will not detail the schema structure extensively.
The official README of prisma-markdown is quite user-friendly, so there was nothing difficult about it. First, install prisma-markdown.
npm i -D prisma-markdown
Then, add the following generator to the schema.prisma file. This generator determines the assets created when the command prisma generate is executed; in this case, it generates a markdown file.
generator markdown {
provider = "prisma-markdown"
output = "./ERD.md"
title = "Sinchon ICPC Camp ERD"
}
After doing this, running the command npx prisma generate will create the file prisma/ERD.md. Opening this file will reveal mermaid code that adequately constructs the table structure and lists the attributes of each table below it.
However, upon opening it in VSCode, the mermaid diagram may not display correctly. To view it, you need to install the Markdown Preview Mermaid Support extension. Other editors likely have similar plugins.
After installing the plugin, opening prisma/ERD.md in preview will allow you to see the mermaid diagram.
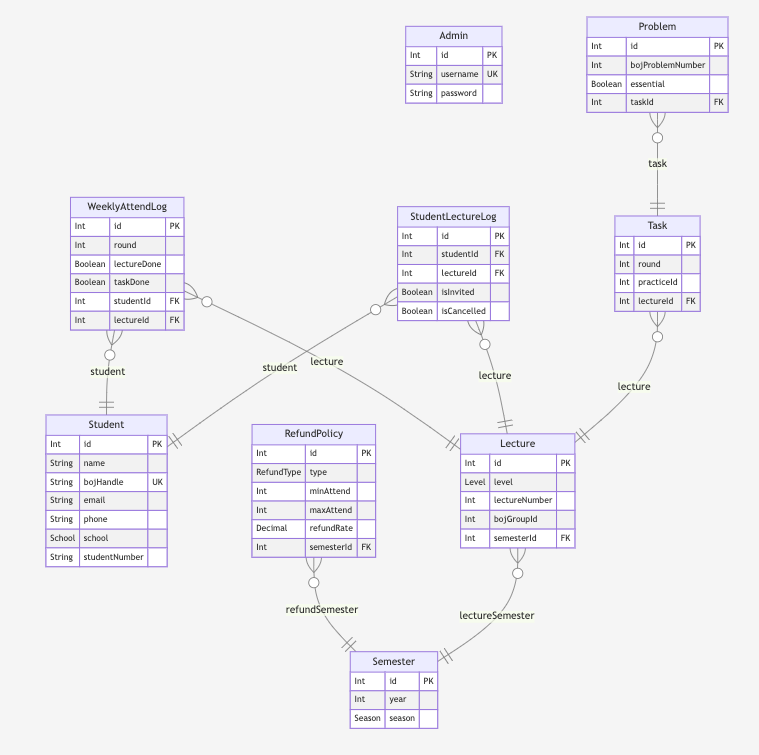
3. Writing Descriptions
Even with the functionality of showing the table structure, I believe the necessity for ERDCloud is significantly reduced. However, it would be even better if there were features to categorize and systematize the tables. This is especially pertinent for large database structures with hundreds of models, where segmenting would naturally enhance visualization.
Hence, prisma-markdown provides the ability to classify tables into various sections within the documentation using @namespace, @erd, and similar annotations.
3.1. @namespace
By adding comments with /// @namespace {name}, a section is created with the provided name. The models tagged with that comment will fall under that section. Of course, a single model can belong to multiple namespaces, so you can simply add @namespace comments with various names. Conversely, models without an @namespace comment will fall under the "default" section.
For example, you can create a section like this for a very simple model that has unique IDs and usernames along with a password for admin accounts.
/// This is admin account information.
///
/// @namespace Admin
model Admin {
/// Primary Key.
id Int @id @default(autoincrement())
/// Admin ID cannot be duplicated.
username String @db.VarChar(255) @unique
password String @db.VarChar(255)
}
This way, the Admin model will appear under the Admin section in the Prisma documentation.

3.2. @erd
While some tables need to belong to specific sections to display their connection relationships, detailed explanations may not be necessary. For instance, consider a Task section that showcases assignments. It would be beneficial to illustrate how a task relates to a specific lecture in the lecture table when visualizing these models, but it may not require an explanation in the Task section.
In such a case, you can add a comment like /// @erd {namespace name}. A key point to note is that the namespace mentioned after @erd must already exist as a namespace declared with @namespace in other models. If the namespace name used appears solely in @erd, it will not be created correctly, and only an ERD diagram will be produced.
/// Lecture information
///
/// Each lecture belongs to a specific semester of a certain year
///
/// Various levels of courses can exist in a single semester
///
/// @namespace Lectures
/// @erd Task
model Lecture {
id Int @id @default(autoincrement())
level Level @default(Novice)
// Total number of rounds in the lecture
lectureNumber Int @default(10)
bojGroupId Int
lectureSemester Semester @relation(fields: [semesterId], references: [id], onDelete: Cascade)
semesterId Int
studentLectureLog StudentLectureLog[]
weeklyAttendLog WeeklyAttendLog[]
task Task[]
@@index([semesterId], map: "semesterId")
}
/// Information about assignments for lectures
/// Each lecture can have multiple assignments
/// Connected to the specific practice ID of the BOJ group of the related lecture
/// @namespace Task
model Task {
id Int @id @default(autoincrement())
round Int
practiceId Int
lecture Lecture @relation(fields: [lectureId], references: [id], onDelete: Cascade)
lectureId Int
problems Problem[]
@@index([lectureId], map: "lectureId")
}
/// Information about problems included in the lecture's assignments
///
/// Each assignment can have multiple problems
///
/// Contains a BOJ problem number and a requirement flag
///
/// @namespace Task
model Problem {
id Int @id @default(autoincrement())
bojProblemNumber Int
essential Boolean @default(true)
task Task @relation(fields: [taskId], references: [id], onDelete: Cascade)
taskId Int
@@index([taskId], map: "taskId")
}
3.3. @describe
The @describe annotation allows you to add descriptions that will appear only in the documentation and not in the ERD diagram. Since it is simply an explanation, it can use a namespace name that is not created with @namespace. However, it is advisable to avoid solely placing descriptions in namespaces not established with @namespace.
3.4. @hidden
The @hidden annotation allows you to completely omit a model from the documentation. The model will not appear in the ERD diagram, nor will it have any descriptions. This can be utilized for tables that are pre-created for future extensions but are currently not in use, or for tables created for testing purposes.
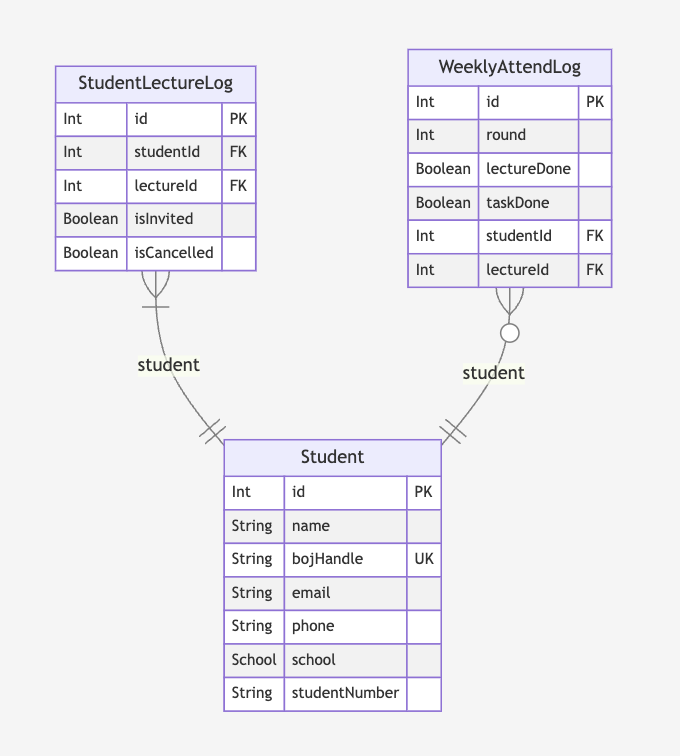
3.5. @minItems 1
In 1:N relationships, there may be instances where N must always be greater than or equal to 1. For instance, a student in the database must have at least one enrollment record. A student without such a record may not need to be managed in the database, so these cases can certainly exist.
The @minItems 1 annotation helps represent this in the diagram. In Prisma's 1:N relationships, the model representing 1 will contain the N side models in an array-like manner. By adding the /// @minItems 1 comment to this array property, it will be reflected in the diagram generated by prisma-markdown.
For example, consider a scenario where the Student model and the StudentLectureLog model represent a 1:N relationship, and students must always hold at least one enrollment history. The @minItems 1 comment can be added to the studentLectureLog property in the Student model.
model Student {
id Int @id @default(autoincrement())
name String @db.VarChar(50)
bojHandle String @db.VarChar(50) @unique
email String
phone String @db.VarChar(20)
school School @default(SOGANG)
studentNumber String @db.VarChar(20) // Student ID
/// @minItems 1
studentLectureLog StudentLectureLog[]
weeklyAttendLog WeeklyAttendLog[]
}
This will indicate in the diagram that the relationship between the Student model and the StudentLectureLog model must contain at least one enrollment record.
3.6. @link
You can link to other models within the documentation using {@link <model name> (<link text>)} (omitting the link text will link to the table name directly). This works because GitHub links automatically generate <a> tags around title-like elements when processing markdown (GitHub Flavored Markdown allows for local conversions with tools such as remark-gfm).
For example, suppose the StudentLectureLog model serves to connect the Student and Lecture models. In this case, in order to link to the document of each model, you can write:
/// Stores each student's course application history
///
/// {@link Student} and {@link Lecture} are connected by this intermediary table
/// Connected via {@link Student.studentLectureLog} property.
model StudentLectureLog {
id Int @id @default(autoincrement())
studentId Int
lectureId Int
student Student @relation(fields: [studentId], references: [id], onDelete: Cascade)
lecture Lecture @relation(fields: [lectureId], references: [id], onDelete: Cascade)
isInvited Boolean @default(false)
isCancelled Boolean @default(false)
@@index([lectureId], map: "lectureId")
@@index([studentId], map: "studentId")
}
If you want to customize the link appearance text rather than using the model name directly, you can follow the model name with the desired text. The following shows an example of appending "Enrollment Log Model" as the link text for the StudentLectureLog model.
/// Manages course applications through the {@link StudentLectureLog Enrollment Log Model}
model Student {
// ...
}
Although this feature was not noted in the official README, it surfaced frequently in example documentation, suggesting its close alignment with official functionality.
4. Using Markdown Syntax
Markdown syntax such as tables or lists is also supported. The official example provides instances of using tables or lists, which are nicely converted in the resulting documentation.
///
/// Product | Section (corner) | Categories
/// --------|------------------|--------------------------------------
/// Beef | Butcher corner | Frozen food, Meat, **Favorite food**
/// Grape | Fruit corner | Fresh food, **Favorite food**
///
/// Furthermore, as `shopping_channel_categories` has a 1:N self-recursive
/// relationship, it is possible to express hierarchies like the below.
/// Hence, each channel can independently set their own category classification.
///
/// - Food > Meat > Frozen
/// - Electronics > Notebook > 15 inches
/// - Miscellaneous > Wallet
///
References
Prisma Generators Documentation
https://www.prisma.io/docs/orm/prisma-schema/overview/generators
221006_Markdown Creation Using Mermaid
I created an ERD and documentation generator for Prisma ORM.
https://oneoneone.kr/content/940dc121
Links related to the official README of prisma-markdown