Creating a Blog - 4. Resolving Image Path Issues
Blog Creation Series
| Title | Link |
|---|---|
| 1. Basic Setup | https://witch.work/posts/blog-remake-1 |
| 2. HTML Design of the Main Page | https://witch.work/posts/blog-remake-2 |
| 3. Structure Design of the Article Detail Page | https://witch.work/posts/blog-remake-3 |
| 4. Enabling Images to be Used with Relative Paths | https://witch.work/posts/blog-remake-4 |
| 5. Enhancing Page Composition and Deployment | https://witch.work/posts/blog-remake-5 |
| 6. Designing Layout of Page Elements | https://witch.work/posts/blog-remake-6 |
| 7. Main Page Component Design | https://witch.work/posts/blog-remake-7 |
| 8. Article List/Content Page Component Design | https://witch.work/posts/blog-remake-8 |
| 9. Automatically Generating Article Thumbnails | https://witch.work/posts/blog-remake-9 |
| 10. Improving Design of Fonts, Cards, etc. | https://witch.work/posts/blog-remake-10 |
| 11. Tracking Views on Articles | https://witch.work/posts/blog-remake-11 |
| 12. Page Themes and Article Search Functionality | https://witch.work/posts/blog-remake-12 |
| 13. Improvements to Theme Icons and Thumbnail Layout | https://witch.work/posts/blog-remake-13 |
| 14. Changing Article Category to be Tag-Based | https://witch.work/posts/blog-remake-14 |
| Optimization of Main Page Operations | https://witch.work/posts/blog-opt-1 |
| Creating Pagination for Article List | https://witch.work/posts/blog-opt-2 |
| Uploading Images to CDN and Creating Placeholders | https://witch.work/posts/blog-opt-3 |
| Implementing Infinite Scroll on Search Page | https://witch.work/posts/blog-opt-4 |
1. Issue Encountered
The blog we previously created can post articles, giving it a blog-like appearance, but there are still issues.
Currently, each article in the blog is stored in a folder named /posts/[slug]/index.md. However, how can we insert images into these articles? I believe it would be best to keep the images in the same folder as the articles for easier relative path access, such as .
The problem is that if we do this, the images cannot be loaded. This is because NextJS only recognizes static resources (images, etc.) that are within the /public directory at build time. Therefore, images inside the /posts directory cannot be accessed at build time, hence we cannot load them.
However, it seems ridiculous to move images to the /public folder every time I write an article in the /posts folder. Additionally, I need to move the images from the many articles I previously wrote to the new blog; handling the image relocations and path changes for dozens of articles is a significant task. Hence, I sought a way to use images located in the same folder as the articles.
I found a solution that someone had already addressed in their blog, and I adapted it for my blog.
The solution is as follows:
- Create a script that moves images from the
/postsdirectory to the/publicdirectory during the build. - Enable relative paths to be recognized as absolute paths.
2. Moving Images to Public During the Build
The solution involves writing a pre-build script that moves images from the /posts directory to the /public directory every time a build occurs. I used a library called fs-extra for this purpose.
First, install fs-extra to handle file operations. Its current size is 59.5KB, which isn't overly burdensome.
npm i fs-extra
Next, create a file named src/bin/pre-build.mjs (the path doesn’t matter as long as it is specified when running the prebuild script).
The reason for using .mjs is to utilize modules and top-level await.
Now, what we need to do is:
- Delete all images of blog posts that are already in
/publicduring the build. - Move all article images from the
/postsdirectory to the/publicdirectory.
Of course, it’s possible to update only the changes, but I don’t think this is necessary for a static site generator.
2.1. Cleaning Existing Public Folder
First, create a /public/images directory for storing blog post images. Then, write the following script in src/bin/pre-build.mjs.
import fsExtra from 'fs-extra';
// Directory to store images
const imageDir = './public/images/posts';
await fsExtra.emptyDir(imageDir);
This script simply empties the imageDir.
2.2. Copying Images
Since images with the same name may exist across different blog post folders, create separate folders for each.
First, define a function that moves images from the source directory to the target directory.
async function copyImage(sourceDir, targetDir, images) {
for (const image of images) {
const sourcePath = `${sourceDir}/${image}`;
const targetPath = `${targetDir}/${image}`;
await fsPromises.copyFile(sourcePath, targetPath);
}
}
Next, define the folder containing the posts.
// Post directory
const postDir = './posts';
Within the posts folder, there are category folders, and within those, there are folders for individual articles. We need to iterate through all of them to copy the images.
const imageFileExtensions = ['.png', '.jpg', '.jpeg', '.gif'];
async function copyPostDirImages() {
// Categories within the posts directory. cs, front...
let postCategories = (await fsPromises.readdir(postDir));
for (const category of postCategories) {
// Read post folders within the category
const posts = await fsPromises.readdir(`${postDir}/${category}`);
for (const post of posts) {
// Files within the post folder
const postFiles = await fsPromises.readdir(`${postDir}/${category}/${post}`);
// Filter only images by extension
const postImages = postFiles.filter((file) => imageFileExtensions.includes(path.extname(file)));
if (postImages.length) {
// Create folder
await fsPromises.mkdir(`${imageDir}/${category}/${post}`, { recursive: true });
await copyImage(`${postDir}/${category}/${post}`, `${imageDir}/${category}/${post}`, postImages);
}
}
}
}
Now we can execute this with await, right?
await fsExtra.emptyDir(imageDir);
await copyPostDirImages();
Then, we can modify the package.json to ensure this script runs before build or dev mode.
{
//...
"scripts": {
/* Add the copyimages command to run our script,
prepending 'pre-' to ensure it runs before build and dev. */
"copyimages": "node ./src/bin/pre-build.mjs",
"prebuild": "npm run copyimages",
"predev": "npm run copyimages",
"dev": "next dev",
"build": "next build",
"start": "next start",
"lint": "next lint"
},
//...
}
Now, let’s run npm run dev!
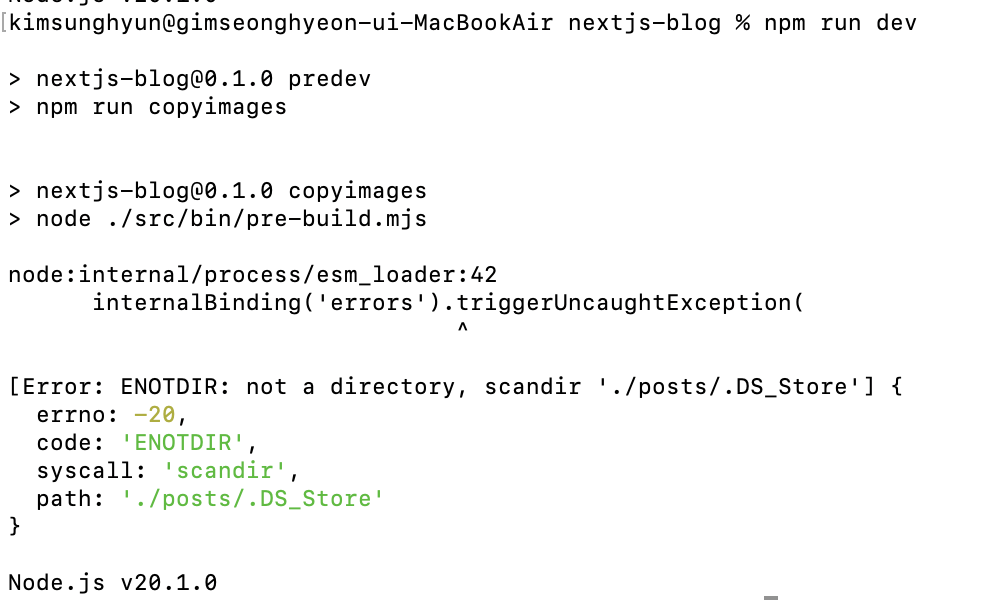
Of course, things don’t go well from the start.
2.3. Resolving Image Copy Issues
The error message indicates that ./posts/.DS_Store is not a directory, and an error occurs because the script tries to scan it as one. The .DS_Store file is automatically created by MacOS for file indexing optimization. Regardless, it’s a file that appears automatically.
We can resolve the issue by simply ignoring this file during the iteration, but let’s improve the list of category and post folders to filter only those which are directories.
To achieve this, we can use the isDirectory function from fs. Let’s try it out.
let postCategories = (await fsPromises.readdir(postDir));
// Filter to include only directories
postCategories = postCategories.filter(category => category.isDirectory());
However, this results in an error stating that isDirectory is not a function. readdir only returns file names as strings. For instance, scanning the /posts folder returns [DS_Store, cs, front, misc]. Since strings do not have an isDirectory method, this error occurs.
Therefore, we need to retrieve file information while performing the readdir. To do this, we can include the withFileTypes: true option.
// Categories within the posts directory. cs, front...
let postCategories = (await fsPromises.readdir(postDir, { withFileTypes: true }));
// Filter to include only directories
postCategories = postCategories.filter(category => category.isDirectory());
Now, we need to be careful. To get the folder names from postCategories, we must access the name property of the fs.Dirent objects in the array.
This results in the following code structure.
async function copyPostDirImages() {
// Categories within the posts directory. cs, front...
let postCategories = (await fsPromises.readdir(postDir, { withFileTypes: true }));
// Filter to include only directories
postCategories = postCategories.filter(category => category.isDirectory());
for (const _category of postCategories) {
// Read post folders within the category
const category = _category.name;
let posts = await fsPromises.readdir(`${postDir}/${category}`, { withFileTypes: true });
// Filter to include only directories
posts = posts.filter(post => post.isDirectory());
for (const _post of posts) {
const post = _post.name;
// Files within the post folder
const postFiles = await fsPromises.readdir(`${postDir}/${category}/${post}`);
// Filter only images by extension
const postImages = postFiles.filter((file) => imageFileExtensions.includes(path.extname(file)));
if (postImages.length) {
// Create folder
await fsPromises.mkdir(`${imageDir}/${category}/${post}`, { recursive: true });
await copyImage(`${postDir}/${category}/${post}`, `${imageDir}/${category}/${post}`, postImages);
}
}
}
}
To streamline the repetitive portions, let’s refactor this into appropriate functions.
const imageFileExtensions = ['.png', '.jpg', '.jpeg', '.gif'];
async function getInnerDirectories(dir) {
const files = await fsPromises.readdir(dir, { withFileTypes: true });
return files.filter(file => file.isDirectory());
}
async function getInnerImages(dir) {
const files = await fsPromises.readdir(dir);
return files.filter((file) => imageFileExtensions.includes(path.extname(file)));
}
async function copyPostDirImages() {
// Categories within the posts directory. cs, front...
const postCategories = await getInnerDirectories(postDir);
for (const _category of postCategories) {
// Read post folders within the category
const category = _category.name;
const posts = await getInnerDirectories(`${postDir}/${category}`);
for (const _post of posts) {
const post = _post.name;
const postImages = await getInnerImages(`${postDir}/${category}/${post}`);
if (postImages.length) {
// Create folder
await fsPromises.mkdir(`${imageDir}/${category}/${post}`, { recursive: true });
await copyImage(`${postDir}/${category}/${post}`, `${imageDir}/${category}/${post}`, postImages);
}
}
}
}
3. Recognizing Relative Paths as Absolute Paths
Once the above tasks are completed, if you write an article in the /posts/cs/os-1 folder and place images in the same path during the build, you should be able to access those images via the /images/posts/cs/os-1/ path. Adjusting the imageDir in the pre-build.mjs file could also allow access through the /posts/cs/os-1 path.
However, it’s quite unlikely that anyone wants to set image URLs as absolute paths like this while writing articles. Therefore, let’s implement functionality to convert these into relative paths. I modified the reference from this source to fit my blog.
3.1. Design of the Method
As mentioned earlier, NextJS only allows static resources located in the /public directory to be used at build time. We have previously moved images from the /posts directory to the /public directory during the build.
So, to use images as relative paths in Markdown (where Markdown refers to both md and mdx files), what should we do?
Markdown files are currently converted into HTML or code through Contentlayer, and during this process, we need to add functionality to replace relative paths specified in the image sources with absolute paths.
Contentlayer allows the use of remark plugins for handling Markdown, so we will utilize a remark plugin.
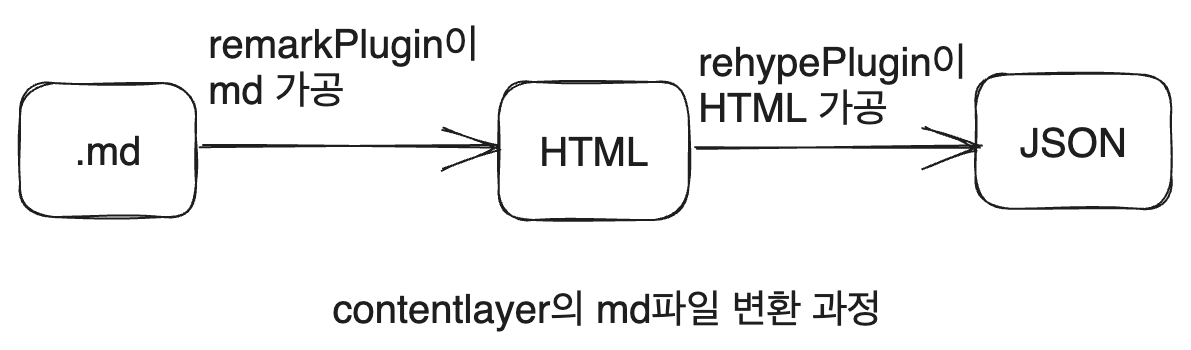
We also need to locate images in the md document. Remark provides functionality to transform md files into AST (Abstract Syntax Tree) represented in JSON object format, which fits our purpose very well.
If you only need the ability to convert Markdown to HTML, using micromark is advisable. While remark can perform this task as well, its focus is more on creating ASTs and providing plugins for conversion (excerpted from remark GitHub README).
Thus, we will create a remark plugin and apply it to Contentlayer.
3.2. Creating the Remark Plugin
Create a file named /src/plugins/change-image-src.mjs. To use ES modules, the .mjs or .ts file extension must be used. However, using TypeScript would require us to utilize the type definitions for Markdown AST, which seems excessive for our purpose, so I opted for .mjs.
In this file, we should ultimately create a plugin that finds the images in the article and converts all their src properties from relative paths to absolute paths. So, where should we start? Let’s structure the plugin first.
A remark plugin function should return a function that takes tree and file as parameters. The tree is the mdast, and the file is an object containing file information provided by Contentlayer. Using this file, we can access the path of the file.
// src/plugins/change-image-src.mjs
export default function changeImageSrc() {
return function(tree, file) {
// Code that does something with tree and file
};
}
The AST generated from converting the md file will pass through this returned function. So, what needs to be done within this function? We need to traverse the tree, find images, and modify their src properties to absolute paths.
For traversal, the syntax tree used by remark is defined in mdast. With this tree, we can traverse the nodes. Furthermore, the format for this universal syntax tree is defined in Unist, with a utility library for traversing it called unist-util-visit. Therefore, let’s install that.
npm install unist-util-visit
By utilizing the visit(tree[, test], visitor[, reverse]) method from this library, we can perform a preorder depth-first search while executing a visitor function for each node to modify the HTML AST.
export default function changeImageSrc() {
return function(tree, file) {
const filePath = file.data.rawDocumentData.flattenedPath;
visit(tree, function() {});
};
}
How do we find the images while traversing the nodes? From looking at the converted HTML from the md articles, all the included images are wrapped in img tags within p tags. We just need to detect this.
To focus on p tags, specify the type of node in the visit function's second argument to execute the visitor function only for this type. According to mdast, the p tag has the type paragraph. So, let’s use this.
Now that we have found the p tags, they will be passed as arguments to the visitor function, where we can search their children for nodes with img tags to modify the URLs.
const imageDirInPublic = 'images/posts';
export default function changeImageSrc() {
return function(tree, file) {
const filePath = file.data.rawDocumentData.flattenedPath;
visit(tree, 'paragraph', function(node) {
const image = node.children.find(child => child.type === 'image');
if (image) {
const fileName = image.url.replace('./', '');
image.url = `/${imageDirInPublic}/${filePath}/${fileName}`;
}
});
};
}
This completes our plugin, which traverses the converted AST, finds img tags within p tags, and modifies their URL.
3.2.1. Explanation of the Image Path Creation
if (image) {
const fileName = image.url.replace('./', '');
image.url = `/${imageDirInPublic}/${filePath}/${fileName}`;
}
This portion needs a bit of explanation.
When constructing the image path, we assume images in the blog will be referenced using relative paths, such as ./A.png (but not encompassing all relative paths like ../). We will assume images will only exist alongside the articles.
Thus, the fileName is created by simply removing the ./ from the existing path.
The file argument we receive in the returned function is converted by Contentlayer, so file.data contains similar information to what was in the converted files within .contentlayer/generated. To obtain paths under /posts, we use file.data.rawDocumentData.flattenedPath, which is the filePath used above.
In addition, the images we will use will exist in /public/images/posts at build time, while the converted articles will be under /posts, but since Contentlayer only processes files within /posts during Markdown conversion, flattenedPath does not contain /posts.
Therefore, to retrieve images through the flattenedPath of the file, we also need to use imageDirInPublic, which provides the path to the images in public. The newly generated image URL is as follows:
image.url = `/${imageDirInPublic}/${filePath}/${fileName}`;
4. Actual Implementation
After completing these tasks, I moved all my existing blog articles and ran a build. It took about 15 seconds to generate the documents. Although further benchmarking can be conducted, it seems reasonable that my blog currently has around 140 articles and about 70 MB of images, taking 15 seconds to build.
There may be opportunities for optimization in the future.
After building, the images corresponding to the articles were successfully placed in public/images/posts. However, since these images are already located in /posts, there’s no reason to upload that folder to GitHub. So, let’s add the folder to .gitignore.
# .gitignore
/public/images/posts
/public/images/posts/*
The next article will address tasks that were previously handled superficially. For example, rather than rendering a temporary array created for the main page, we will properly display a list of articles and create a complete article list page.
References
Someone else has already faced similar concerns. Therefore, I referred to their article. https://www.codeconcisely.com/posts/nextjs-storing-images-next-to-markdown/
For creating a remark plugin, I referred to the explanation from the remark GitHub repository. https://github.com/remarkjs/remark
https://github.com/syntax-tree/mdast
https://github.com/syntax-tree/unist
https://swizec.com/blog/how-to-build-a-remark-plugin-to-supercharge-your-static-site/